Artykuł AFIN.NET:
AFIN.NET.TextConverter © AFIN 2001-2009
Wojciech Gardziński, 2009.03
Folder z przykładami:
http://afin.net/samples/AFIN.NET.TextConverter/Cases/
AFIN.NET.TextConverter -
- niezależny, nieograniczony, uniwersalny i zautomatyzowany dostęp do
dowolnych danych Twojego systemu informatycznego
Summary:
About 90% of the access to
the OLTP (transactional) system is realized by data exports from OLTP system
and imports into Excel. Exports are badly formatted, prepared as „for
printing”. The analysts want the data – but reading it is very difficult not
for technological but for logical reasons.
AFIN.NET.TextConverter
offers an independend, unlimited, universal and automatized access to your own
data exported by OLTP systems. AFIN.NET.TextConverter (ex „UNIKON”) is an
integral part of the AFIN.NET system.
Samples folder: http://afin.net/samples/AFIN.NET.TextConverter/Cases/
1. Wstęp – opis problemu
W ogromnej większości
przypadków, analitycy finansowi dostają się do swoich danych poprzez import do
Excela eksportów z innych systemów informatycznych.
Dzieje się tak, pomimo
technologicznej dostępności danych, istnienia podsystemów raportujących, wielu
innych, pozornych ułatwień (np. eksporty do PDF lub HTML), oferowanych przez
systemy informatyczne, a nawet posiadania specjalistycznych hurtowni danych lub
systemów klasy Business Intelligence. Oczywiście, dostawcy i konsultanci tych
systemów, twierdzą, że jest to wina klienta, gdyż nie zakupił on czegoś, albo
nie wdrożył odpowiednio, albo … (Tu można wpisać powód dowolny, unikający
jasnej odpowiedzi, dlaczego tego nie ma.)
Pewnego rodzaju „rekordem”
jest zakup systemu BI w celu uzyskiwania z niego uporządkowanych wydruków
tekstowych do dalszej obróbki w Excelu – przykład rzeczywisty(!)
Import tekstu to, od strony
technologicznej, temat powszechnie znany i informatycznie dopracowany.
Wszystkie, dosłownie wszystkie, systemy analityczne importują pliki tekstowe
bez najmniejszego problemu, oferując do tego specjalne kreatory i nie jest to
proces ani technologicznie, ani użytkowo, skomplikowany.
Dlaczego więc sprawia on nam, analitykom tyle
kłopotu?
Po pierwsze:
Import tekstu jest pracochłonny i bardzo trudno go
zautomatyzować
Eksporty do plików
tekstowych są traktowane jako „wydruki”. Zawierają mnóstwo dodatkowych
„upiększeń”, jak nagłówki, tabelki, podsumowania, itp., jak również dane w nich
zawarte są często dzielone na kilka wierszy, a w przypadkach wydruków
„rejestrowych”, teksty takie posiadają nawet swoistą strukturę (więcej o tym
poniżej).
Aby to wszystko odśmiecić
ręcznie (= w Excelu) trzeba włożyć dużo wysiłku, a w przypadku wydruków
hierarchicznych, jest to nawet niemożliwe bez kopiowania i przeklejania danych.
Idąc dalej, aby to zautomatyzować, analitycy… uczą się Visual Basica (!), gdyż uważają, że jak coś się robi pracochłonnie, to jedynym
sposobem automatyzacji jest stworzenie własnego makra. Makro takie przyspiesza,
owszem, przeklejanie…, ale architektura pracy (błędna) pozostaje bez zmian.
Zapraszamy do lektury pogłębionej
analizy architektury informatycznej firmy – istniejącej i pożądanej (optymalnej
z punktu widzenia analizy danych w Excelu i AFIN.NET).
Po drugie:
Import tekstu jest AWARYJNY,
tzn. Excel, importując dane, próbuje, za wszelką cenę, zakwalifikować je do
któregoś ze znanych sobie formatów i, w większości przypadków, robi to źle.
Dane tekstowe, umieszczone w
cudzysłowach, są często dzielone lub pomijane, dane tekstowe, podobne do
znanych formatów Excela, są zamieniane na wartości numeryczne i odpowiednio do
tego formatowane, dane numeryczne z kolei, wpisywane są często jako tekst –
wystarczy, że domyślny separator tysięczny systemu analityka jest inny, niż
zastosowany na wydruku.
W wielu przypadkach, nawet gdy wszystkie, powyższe warunki są spełnione, import
tekstu i tak jest błędny i trzeba go poprawiać ręcznie.
Po trzecie:
Największą wadą wszelkich
procedur importowych jest jednak to, że traktują one każdy WIERSZ TEKSTU jako
WIERSZ DANYCH.
Tymczasem, takie podejście
dotyczyć może tylko niewielu eksportów, dedykowanych ku dalszej obróbce. A te,
są z kolei albo niedostępne, albo z punktu widzenia analityka, mało ciekawe –
nie zawierają potrzebnych danych lub zawierają je w innym układzie.
Zawierają
więc dane śmieciowe lub dane
umieszczone są w wielu wierszach, często dodatkowo przesuniętych w kolumnach.
Po czwarte:
Podstawowy problem importu
danych polega NA LOGICE takiego odczytu. Dane, zanim się je w ogóle „odczyta”,
najpierw muszą być „znalezione”, a informacja o tym, czy dany wiersz jest
wartościowy, czy też nie, bywa zwykle w innym miejscu, niż same dane do
odczytania (np. w innym wierszu). Gdy zostaną odczytane, muszą też zostać
zinterpretowane i dołączone do odpowiedniego „nagłówka” w strukturze. A gdy już
nawet to wszystko połączymy, trzeba jasno wskazać, kiedy należy dany rekord
zapisać i rozpocząć gromadzenie kolejnego zestawu danych do zapisu.
To, co wygląda prosto, wręcz
banalnie, dla człowieka – dla twórcy algorytmu (logiki) odczytu bywa zadaniem
bardzo niekiedy trudnym.
I, naprawdę, czasami trudno
oprzeć się wrażeniu, że taka, a nie inna, konstrukcja wydruku, jest stworzona
złośliwie, aby trudniej było wyciągnąć z niej dane, a tym samym być zmuszonym
do kolejnych zakupów (raportów, dodatków, usług) u dostawcy danego systemu.
2. Analitycy chcą danych!
A systemy informatyczne,
tworzone przez informatyków, potrzeby tej nie spełniają lub robią to źle.
Z jednej strony oferują
nieciekawe eksporty, uporządkowane informatycznie, z drugiej zaś wydruki
tekstowe lub eksporty do PDF, HTML, Excela, Worda, sporządzone tak, że trudno
coś z nich odczytać.
Celem tych wydruków jest
„atrakcyjnie wyglądać na drukarce”, a to, że stanowią one niekiedy jedyne
źródło sensownych danych, zdaje się dostawcy systemu nie obchodzić, choć często
o tym doskonale wie.
Wszelkie procedury importowe
pobierają WSZYSTKIE wiersze, potem w Excelu się je filtruje, obrabia, czyści i
„układa” we właściwe kolumny. Jest to niepowtarzalne i bardzo pracochłonne, ale
też niekiedy dodatkowo utrudnione, gdyż rozmiar pliku tekstowego często przekracza (bo np. zawiera nagłówki) dopuszczalną liczbę
wierszy, akceptowaną przez arkusz Excela. Importy takie są
więc dzielone na mniejsze i po imporcie i przefiltrowaniu (każda część
osobno) sklejane z powrotem w kolejnym arkuszu.
Z drugiej strony, systemy te
oferują wydruki „merytoryczne”, w których informacja jest już wyselekcjonowana,
merytorycznie przetworzona, uzupełniona danymi słownikowymi i … prezentowana w
jeszcze bardziej atrakcyjnej wizualnie formie. Ta „wizualna atrakcyjność”
jednak jest już jednak całkowitym zaprzeczeniem efektywności importu danych.
Przykłady takich zestawień
to „Zestawienie obrotów i sald programu FK” lub „Zestawienie rozrachunków
nierozliczonych”
Przyjrzyjmy się
przykładom:
Problem: Zaśmiecenie
wydruku:
(Mnóstwo linii dodatkowych)
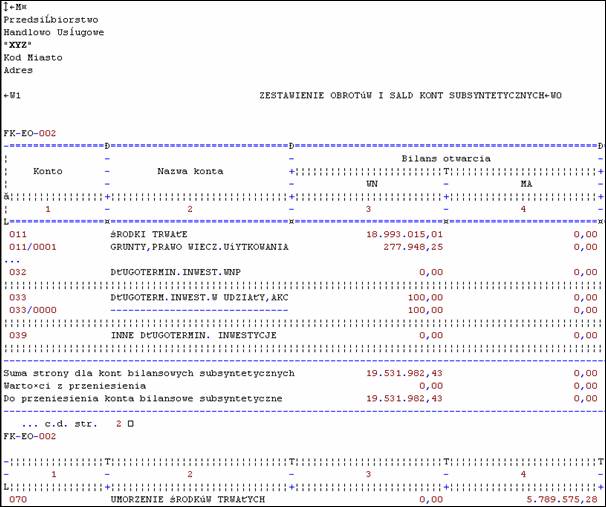
Problem: Hierarchia danych
(Jak odczytać, że 1.dokument o wartości 38,28 został zaksięgowany na
koncie=401002 dla MPK=Zarząd?)

Problem: Przesunięcie danych
w poziomie (kolumnach)
(Elementy tabeli dla
dokumentów są w innych kolumnach, niż podsumowania)

Problem: Przesunięcie danych
w pionie (wierszach)
(Wartości „Ma” są poniżej
wartości „Winien” – odczyt wierszami jest bezużyteczny, trudno przyporządkować
dane „ma” do odp. konta)

Problem: Dane w PDF, HTML, Plikach
MS Word
(Prosty przykład, bywa dużo
gorzej…)

3. Co oferuje AFIN.NET.TextConverter?
- Filtrownie
wierszy przed ich jakąkolwiek
obróbką (wycięcie nagłówków i wierszy nieistotnych, np. podsumowania
stron, informacje „z przeniesienia”)
- Dowolną
definicję odczytu danych, tj.
rozpoznanie wiersza po dowolnych znakach i odczyt dowolnej informacji albo
jako tekst, albo jako wartość, przy czym, zdefiniowany przez użytkownika
format pola danych jednoznacznie określa typ danych przy dalszej analizie
w Excelu
- Dla wartości liczbowych można dowolnie ustalać znaki separatorów tysięcznych i
dziesiętnych – przy imporcie poprzez ODBC jest to niedopracowane i
powoduje mnóstwo błędów.
- Można stosować własne formuły obliczeniowe już podczas importu danych.
Odciąża nam to potem nasze arkusze analityczne i oznacza nieograniczone możliwości odpowiedniej interpretacji odczytywanej wartości, np. wyliczanie roku, miesiąca, a nawet kwartału, czy też dnia tygodnia z daty i to zapisanej w dowolnym formacie, np. tak „090131”.
Stosowanie formuł ma również dzisiątki innych zastosowań. - Można odczytywać dane hierarchiczne z dowolnej ilości stopni struktury.
- Proces można
zautomatyzować.
AFIN.NET.TextConverter można uruchamiać ręcznie, w trybie programowym (z makra), można go stosować dla jednego pliku albo dla wielu plików, określonych wzorcem nazwy. - Narzędzie jest uniwersalne, tzn. steruje się nim parametrycznie.
Wystarczy uruchomić procedurę na odpowiednio skonfigurowanym arkuszu
Excela, a program odczyta z niego parametry i wykona odczyt pliku
- Działa w 3 podstawowych trybach pracy
- Definicji ustawień
- Dopracowywania ustawień – próbne importy
- Normalnej pracy
- Zapisuje tabelę danych do dowolnego formatu bazodanowego, obsługiwanego przez ADO,
tj. może to być m.in. Excel, Access, SQL Server, DBF i setki innych, po
określeniu tzw. „ciągu połączenia bazodanowego”. Przykłady takiech ciągów
dla baz standardowych są podane w przykładach - w liście wyboru bazy
wynikowej.
- Pracując w trybie testowym, umożliwia również
dowolne ograniczenie ilości pobieranych wierszy. Gdy tekst jest duży, a
operator nie może lub nie chce tracić kilku minut na każdą iterację
odczytu próbnego, może ograniczyć ilość pobieranych wierszy tekstu. Próby
kończą się wtedy szybciej, umożliwiając szybkie poprawki i kolejne próby
- AFIN.NET.TextConverter (d. „UNIKON”) jest obecnie
integralną częścią systemu AFIN.NET i podlega tym samym zasadom pracy.
Nie trzeba się go specjalnie uczyć, ani specjalnie wdrażać.